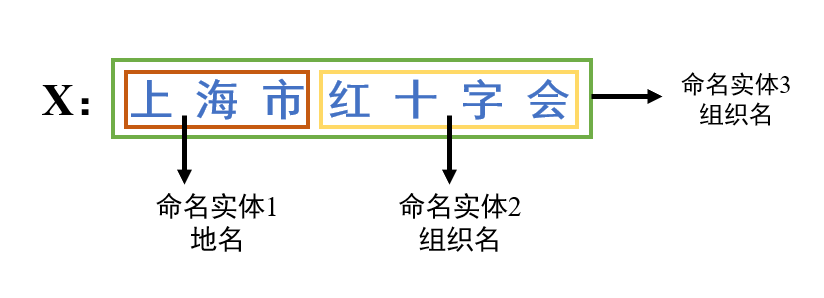
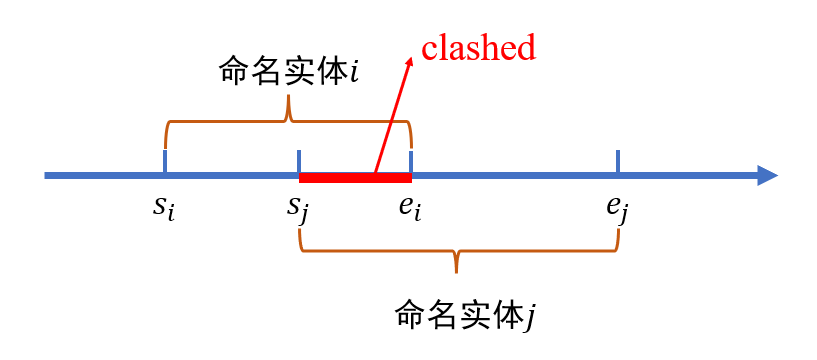
过去一共主要有四类范式用来解决嵌套命名实体识别任务:
① 基于序列标注(sequence labeling)的框架;
② 基于超图(hypergraph)的框架;
③ 基于序列到序列(Seq2Seq)的框架;
④ 基于片段分类(span classification)的框架。
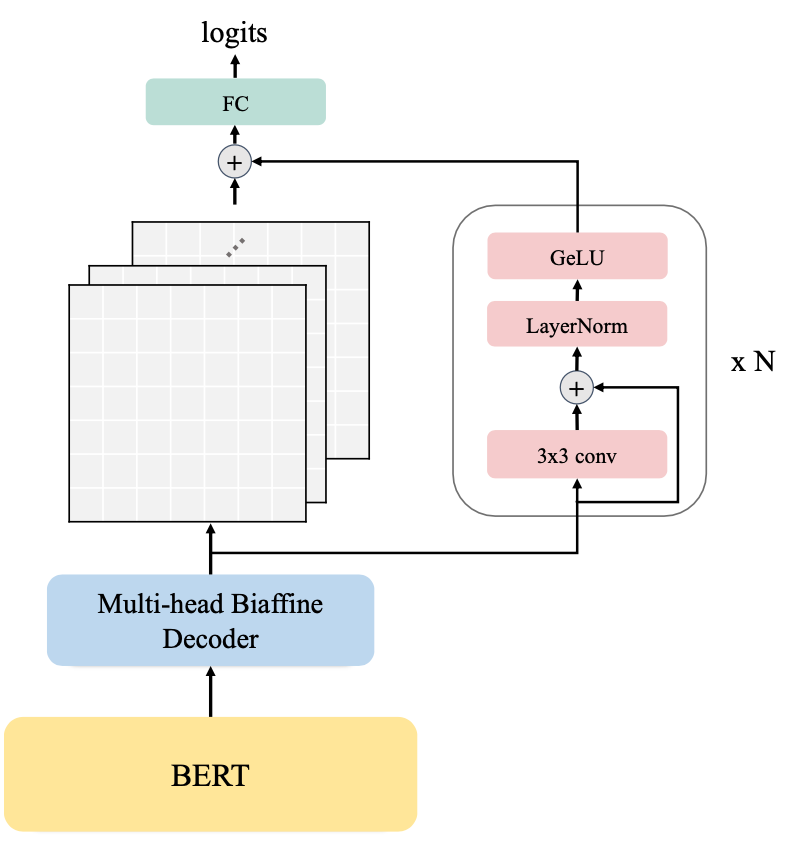
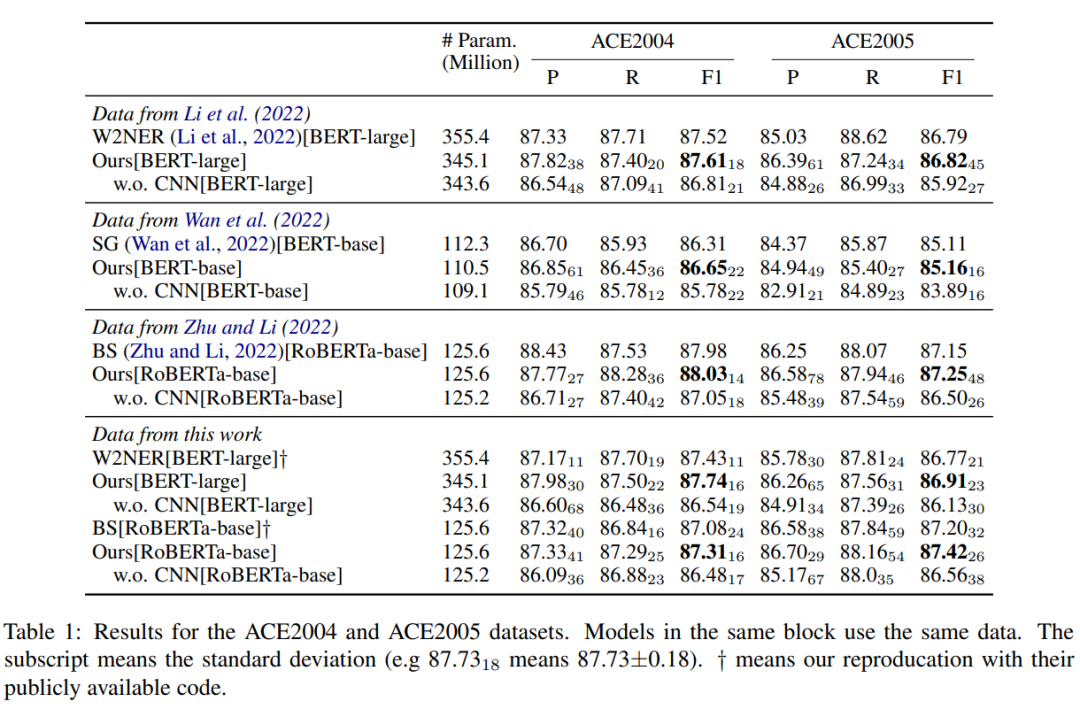
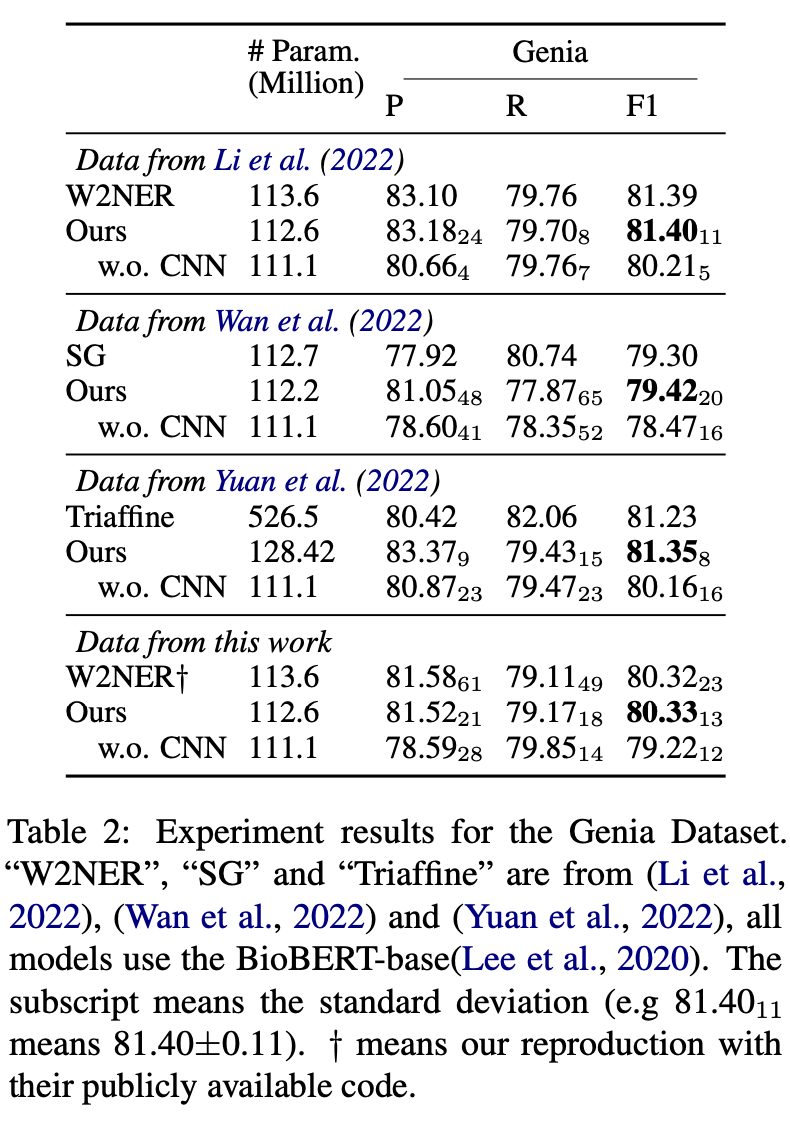
本文跟进了《Named Entity Recognition as Dependency Parsing》这一论文的工作,同样采用了基于片段分类的解决方案。该论文提出采用起始和结束词来指明(pinpoint)对应片段,并利用双仿射解码器(Biaffine Decoder)来得到一个评分矩阵(score matrix),其元素(i , j)代表对应片段(开始位置为第 i 个词,结束位置为第 j 个词)为实体的分数。这一基于片段的方法在计算上易于并行,因此得到了广泛的采用。
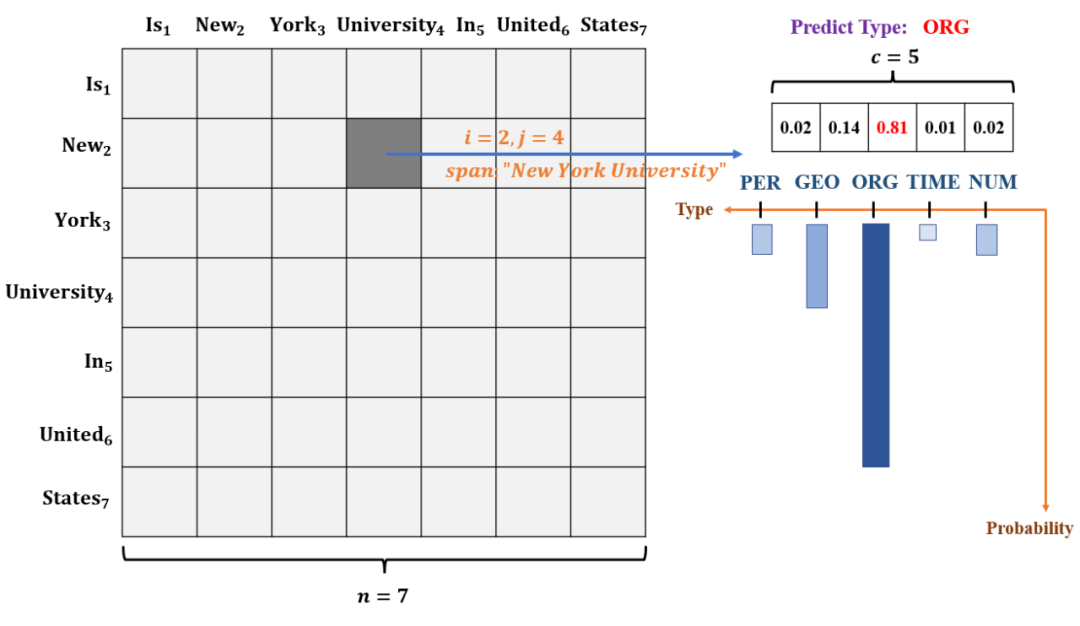
考虑一共有种不同类型的命名实体,对于每一个长度为 n 的输入序列,模型输出的评分矩阵的形状为 n*n*c 。
一方面我们可以将这个张量理解成一个 n*n 的方阵,其中方阵的每个位置的元素都是一个 c 维向量,可以用于表示该位置对应文本片段的命名实体类别分布。而这个n*n的方阵与输入序列的文本片段之间的映射是通过方阵元素的位置编码的,即使用方阵的第 i 行第 j 列的元素对应的维向量来表示原输入序列的第 i 个词到第 j 个词组成文本片段对应的实体类别分布(在矩阵的下三角区域, i>j ,对应的文本片段为第 j 个词到第 i 个词)。
下图(3)给出了一个形象的例子来帮助读者理解评分矩阵。



 发表于 2022-9-22 16:46:33
发表于 2022-9-22 16:46:33