|
|
将网易云音乐歌单完整导出,我自己试过很多方法,几乎全部以失败告终,最后几乎找遍全网所有的论坛和网上资源,找到目前可行的方法:将别人的歌单变成自己的歌单(自己新建一个歌单,然后全选别人的歌单里面歌曲,添加到自己新建的歌单里面)——具体原因稍后解释。然后在网页端的网易云音乐里面打开自己的歌单页面,按下F12进入控制台(console),切换iframe。
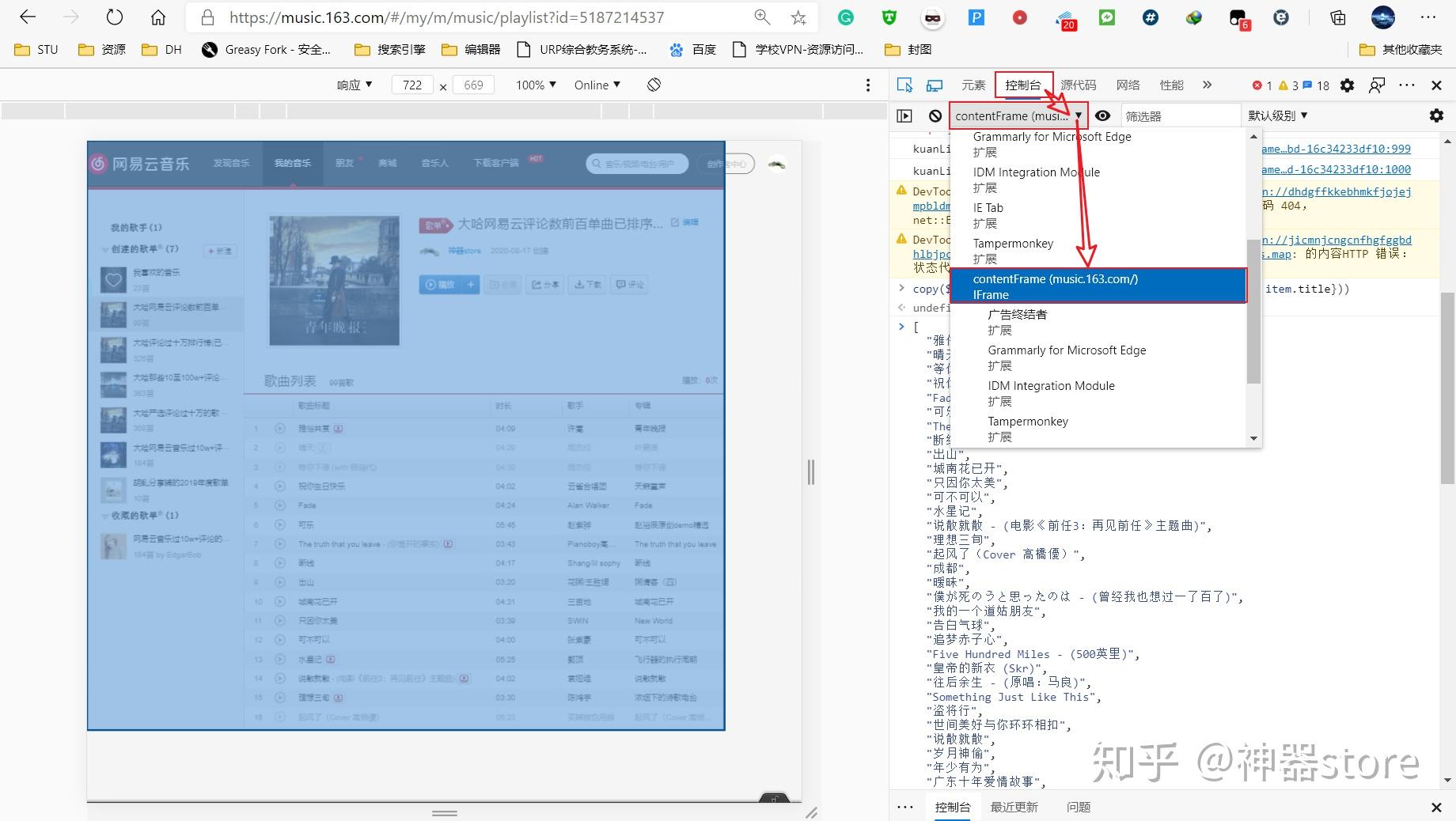
接下来有两种方法可以得到歌单的歌曲列表:
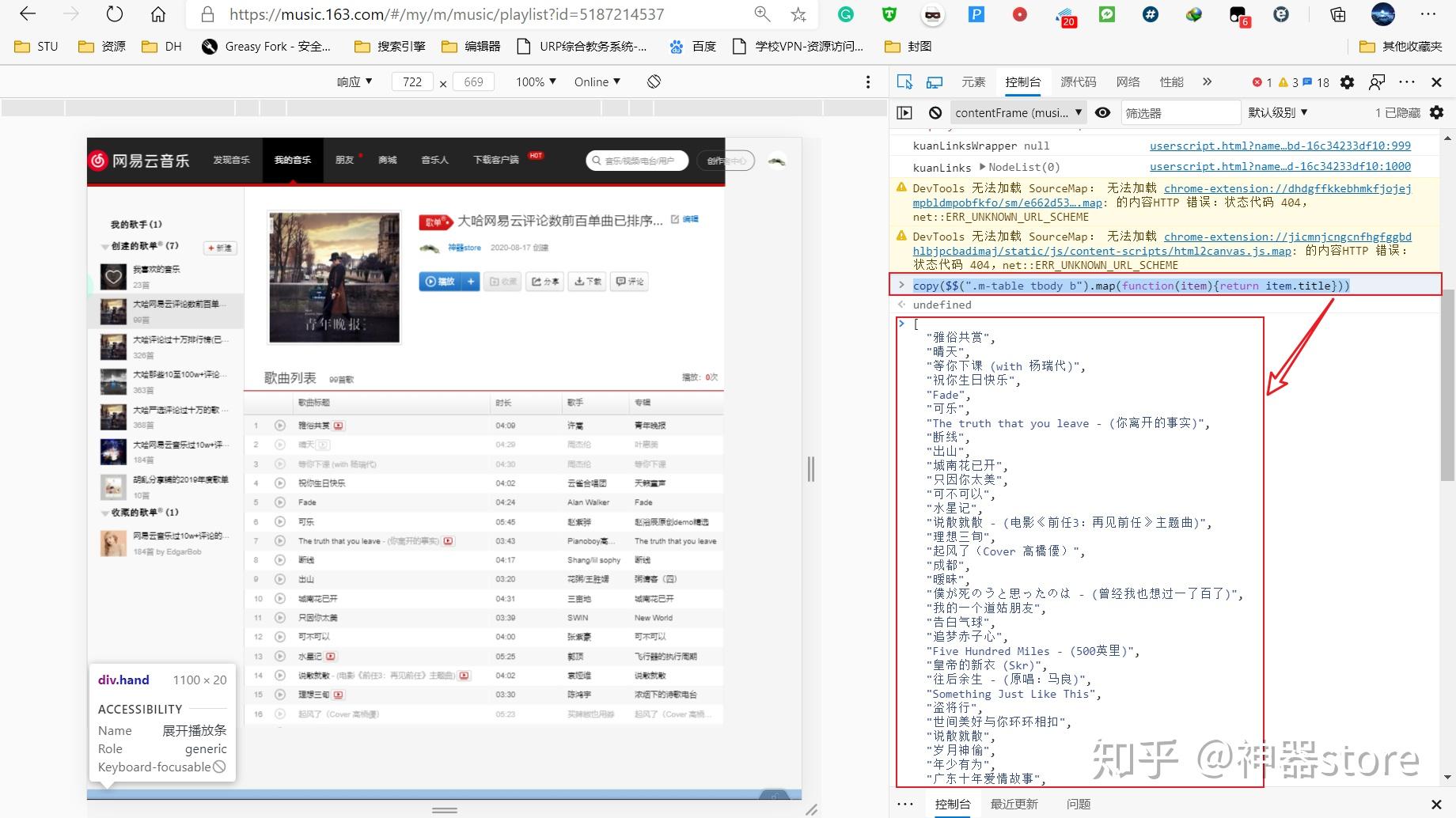
(方法一)粘贴代码1:
copy($$(".m-table tbody b").map(function(item){return item.title}))按下回车,有可能列表加载不出来,在下一行按下快捷键“Ctrl V”,歌单的歌曲列表就出来了,之后就可以随便复制了,这样的得到的歌单列表仅有歌名!
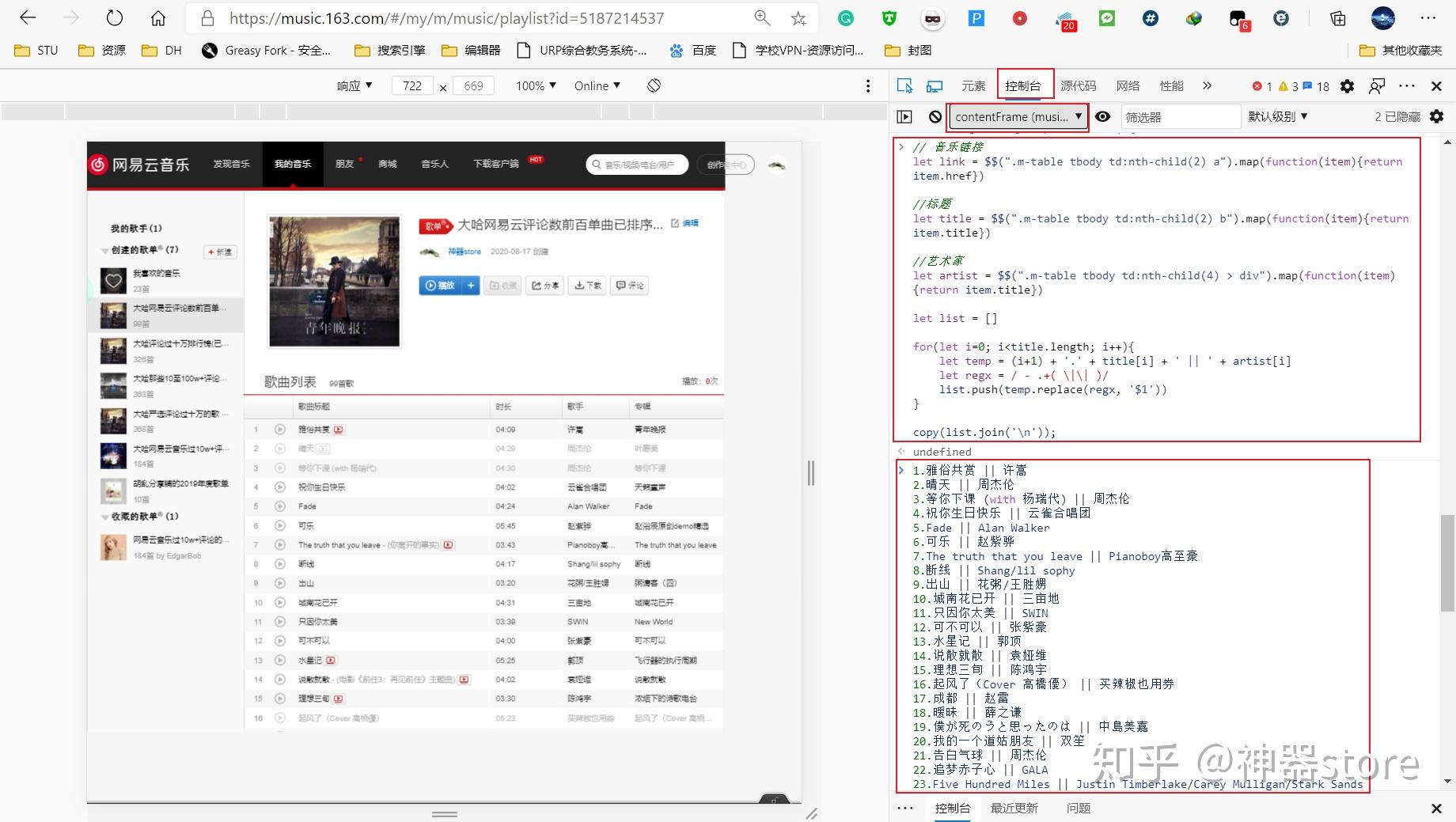
<hr/>(方法二)粘贴代码2:
// 音乐链接
let link = $$(&#34;.m-table tbody td:nth-child(2) a&#34;).map(function(item){return item.href})
//标题
let title = $$(&#34;.m-table tbody td:nth-child(2) b&#34;).map(function(item){return item.title})
//艺术家
let artist = $$(&#34;.m-table tbody td:nth-child(4) > div&#34;).map(function(item){return item.title})
let list = []
for(let i=0; i<title.length; i++){
let temp = (i+1) + &#39;.&#39; + title + &#39; || &#39; + artist
let regx = / - .+( \|\| )/
list.push(temp.replace(regx, &#39;$1&#39;))
}
copy(list.join(&#39;\n&#39;));按下回车,有可能列表加载不出来,在下一行按下快捷键“Ctrl V”,歌单的歌曲列表就出来了,之后就可以随便复制了!这样得到的歌单列表有序号+歌名+歌手。
<hr/>为什么要将别人的歌单变成自己的歌单,这是因为如果你直接在别人的歌单页面执行如上同样的操作,只能得到歌单前10首歌曲,无法得到全部歌曲列表!
<hr/><hr/><hr/>我也试过通过Python爬取歌单列表的方式获取,无一例外,全部失败了,也是一样的原因,只能得到歌单前十首歌曲的信息,其余的无法获取(官方的排行榜可以全部获得,如网易云音乐热歌榜、新歌榜等)!例如:下面的代码是爬取网易云音乐某歌单列表并导出歌名和下载地址
import requests
from bs4 import BeautifulSoup
import urllib.request
from lxml import html
etree = html.etree
headers = {
&#34;Referer&#34;: &#34;https://music.163.com/&#34;,
&#34;Host&#34;: &#34;music.163.com&#34;,
&#34;user-agent&#34;: &#34;Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/81.0.4044.138 Safari/537.36 Edg/81.0.416.72&#34;,
&#34;Accept&#34;: &#34;text/html,application/xhtml+xml,application/xml;q=0.9,image/webp,image/apng,*/*;q=0.8,application/signed-exchange;v=b3;q=0.9&#34;
}
# 歌单url 通过网易云获取自己的链接
play_url = &#34;https://music.163.com/playlist?id=5186898701&#34;
# 请求url
response = requests.get(play_url, headers=headers).content
# 使用bs4匹配出对应的歌曲名称以及地址
s = BeautifulSoup(response, &#34;lxml&#34;)
main = s.find(&#34;ul&#34;, {&#34;class&#34;: &#34;f-hide&#34;})
# print(main.find_all(&#34;a&#34;))
lists = []
for music in main.find_all(&#34;a&#34;):
music_list = []
musicUrl = &#39;http://music.163.com/song/media/outer/url&#39; + music[&#39;href&#39;][5:] + &#39;.mp3&#39;
musicName = music.text
music_list.append(musicName)
music_list.append(musicUrl)
# 全部歌曲信息放在lists列表中
lists.append(music_list)
# lists = str(lists)
# 保存歌曲名称以及歌曲url
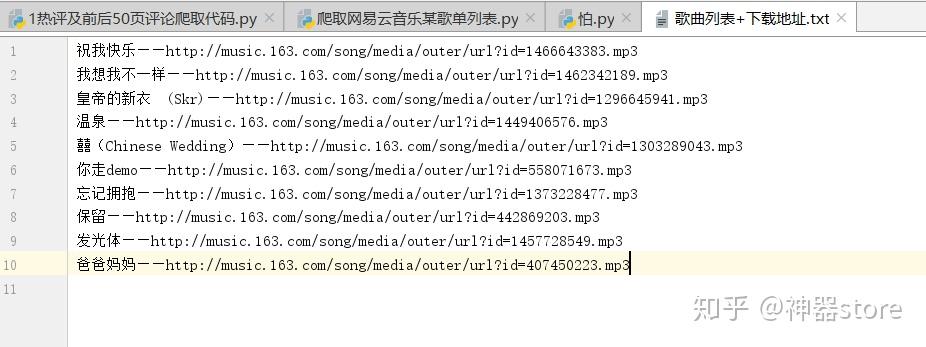
with open(&#34;歌曲列表+下载地址.txt&#34;, &#34;a&#34;, encoding=&#34;utf-8&#34;) as f:
f.write(musicName + &#34;——&#34; + musicUrl + &#34;\n&#34;)运行结果如下图:一百多首歌曲的歌单只能得到10首歌曲!
我还将以前爬取网易云音乐热歌榜音乐评论的代码进行修改以获取某歌单的音乐列表,结果还是失败了,照旧,只能获得该歌单前10首音乐,其余的无法获取!原因未知,代码如下:
# -*- coding:utf-8 -*-
&#34;&#34;&#34;
爬取网易云音乐热歌榜的最新评论,指定页数的所有评论,比如前n页(原代码,现已将爬取评论的代码删除,仅获取歌名和歌曲评论数量)
2020年8月18日
&#34;&#34;&#34;
import os
import re
import math
import random
import urllib.request
import urllib.error
import urllib.parse
from Crypto.Cipher import AES
import base64
import requests
import json
import time
import csv
agents = [
&#34;Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/537.1 (KHTML, like Gecko) Chrome/22.0.1207.1 Safari/537.1&#34;,
&#34;Mozilla/5.0 (X11; CrOS i686 2268.111.0) AppleWebKit/536.11 (KHTML, like Gecko) Chrome/20.0.1132.57 Safari/536.11&#34;,
&#34;Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/536.6 (KHTML, like Gecko) Chrome/20.0.1092.0 Safari/536.6&#34;,
&#34;Mozilla/5.0 (Windows NT 6.2) AppleWebKit/536.6 (KHTML, like Gecko) Chrome/20.0.1090.0 Safari/536.6&#34;,
&#34;Mozilla/5.0 (Windows NT 6.2; WOW64) AppleWebKit/537.1 (KHTML, like Gecko) Chrome/19.77.34.5 Safari/537.1&#34;,
&#34;Mozilla/5.0 (X11; Linux x86_64) AppleWebKit/536.5 (KHTML, like Gecko) Chrome/19.0.1084.9 Safari/536.5&#34;,
&#34;Mozilla/5.0 (Windows NT 6.0) AppleWebKit/536.5 (KHTML, like Gecko) Chrome/19.0.1084.36 Safari/536.5&#34;,
&#34;Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/536.3 (KHTML, like Gecko) Chrome/19.0.1063.0 Safari/536.3&#34;,
&#34;Mozilla/5.0 (Windows NT 5.1) AppleWebKit/536.3 (KHTML, like Gecko) Chrome/19.0.1063.0 Safari/536.3&#34;,
&#34;Mozilla/5.0 (Macintosh; Intel Mac OS X 10_8_0) AppleWebKit/536.3 (KHTML, like Gecko) Chrome/19.0.1063.0 Safari/536.3&#34;,
&#34;Mozilla/5.0 (Windows NT 6.2) AppleWebKit/536.3 (KHTML, like Gecko) Chrome/19.0.1062.0 Safari/536.3&#34;,
&#34;Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/536.3 (KHTML, like Gecko) Chrome/19.0.1062.0 Safari/536.3&#34;,
&#34;Mozilla/5.0 (Windows NT 6.2) AppleWebKit/536.3 (KHTML, like Gecko) Chrome/19.0.1061.1 Safari/536.3&#34;,
&#34;Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/536.3 (KHTML, like Gecko) Chrome/19.0.1061.1 Safari/536.3&#34;,
&#34;Mozilla/5.0 (Windows NT 6.1) AppleWebKit/536.3 (KHTML, like Gecko) Chrome/19.0.1061.1 Safari/536.3&#34;,
&#34;Mozilla/5.0 (Windows NT 6.2) AppleWebKit/536.3 (KHTML, like Gecko) Chrome/19.0.1061.0 Safari/536.3&#34;,
&#34;Mozilla/5.0 (X11; Linux x86_64) AppleWebKit/535.24 (KHTML, like Gecko) Chrome/19.0.1055.1 Safari/535.24&#34;,
&#34;Mozilla/5.0 (Windows NT 6.2; WOW64) AppleWebKit/535.24 (KHTML, like Gecko) Chrome/19.0.1055.1 Safari/535.24&#34;
]
headers = {
&#39;Host&#39;:&#39;music.163.com&#39;,
&#39;Origin&#39;:&#39;https://music.163.com&#39;,
&#39;Referer&#39;:&#39;https://music.163.com/song?id=28793052&#39;,
&#39;User-Agent&#39;:&#39;&#39;.join(random.sample(agents, 1))
}
# 除了第一个参数,其他参数为固定参数,可以直接套用
# offset的取值为:(评论页数-1)*20,total第一页为true,其余页为false
# 第一个参数
# first_param = &#39;{rid:&#34;&#34;, offset:&#34;0&#34;, total:&#34;true&#34;, limit:&#34;20&#34;, csrf_token:&#34;&#34;}&#39;
# 第二个参数
second_param = &#34;010001&#34;
# 第三个参数
third_param = &#34;00e0b509f6259df8642dbc35662901477df22677ec152b5ff68ace615bb7b725152b3ab17a876aea8a5aa76d2e417629ec4ee341f56135fccf695280104e0312ecbda92557c93870114af6c9d05c4f7f0c3685b7a46bee255932575cce10b424d813cfe4875d3e82047b97ddef52741d546b8e289dc6935b3ece0462db0a22b8e7&#34;
# 第四个参数
forth_param = &#34;0CoJUm6Qyw8W8jud&#34;
# 获取参数
def get_params(page): # page为传入页数
iv = &#34;0102030405060708&#34;
first_key = forth_param
second_key = 16 * &#39;F&#39;
if(page == 1): # 如果为第一页
first_param = &#39;{rid:&#34;&#34;, offset:&#34;0&#34;, total:&#34;true&#34;, limit:&#34;20&#34;, csrf_token:&#34;&#34;}&#39;
h_encText = AES_encrypt(first_param, first_key, iv)
else:
offset = str((page-1)*20)
first_param = &#39;{rid:&#34;&#34;, offset:&#34;%s&#34;, total:&#34;%s&#34;, limit:&#34;20&#34;, csrf_token:&#34;&#34;}&#39; % (offset,&#39;false&#39;)
h_encText = AES_encrypt(first_param, first_key, iv)
h_encText = AES_encrypt(h_encText, second_key, iv)
return h_encText
# 获取 encSecKey
def get_encSecKey():
encSecKey = &#34;257348aecb5e556c066de214e531faadd1c55d814f9be95fd06d6bff9f4c7a41f831f6394d5a3fd2e3881736d94a02ca919d952872e7d0a50ebfa1769a7a62d512f5f1ca21aec60bc3819a9c3ffca5eca9a0dba6d6f7249b06f5965ecfff3695b54e1c28f3f624750ed39e7de08fc8493242e26dbc4484a01c76f739e135637c&#34;
return encSecKey
# 解密过程
def AES_encrypt(text, key, iv):
pad = 16 - len(text) % 16
text = text + pad * chr(pad)
encryptor = AES.new(key, AES.MODE_CBC, iv)
encrypt_text = encryptor.encrypt(text)
encrypt_text = base64.b64encode(encrypt_text)
encrypt_text = str(encrypt_text, encoding=&#34;utf-8&#34;) # 注意一定要加上这一句,没有这一句则出现错误
return encrypt_text
# 获得评论json数据
def get_json(url, params, encSecKey):
data = {
&#34;params&#34;: params,
&#34;encSecKey&#34;: encSecKey
}
response = requests.post(url, headers=headers, data=data)
return response.content.decode(&#39;utf-8&#39;) # 解码
# 获取热歌榜所有歌曲名称和id
def get_all_hotSong():
url = &#39;https://music.163.com/playlist?id=5186898701&#39; # 网易云云音乐热歌榜url
header = {&#39;User-Agent&#39;: &#39;&#39;.join(random.sample(agents, 1))} # random.sample() 的值是列表, &#39;&#39;.join()转列表为字符串
request = urllib.request.Request(url=url, headers=header)
html = urllib.request.urlopen(request).read().decode(&#39;utf8&#39;) # 打开url
html = str(html) # 转换成str
# print(html)
pat1 = r&#39;<ul class=&#34;f-hide&#34;><li><a href=&#34;/song\?id=\d*?&#34;>.*</a></li></ul>&#39; # 进行第一次筛选的正则表达式
result = re.compile(pat1).findall(html) # 用正则表达式进行筛选
# print(result)
result = result[0] # 获取tuple的第一个元素
pat2 = r&#39;<li><a href=&#34;/song\?id=\d*?&#34;>(.*?)</a></li>&#39; # 进行歌名筛选的正则表达式
pat3 = r&#39;<li><a href=&#34;/song\?id=(\d*?)&#34;>.*?</a></li>&#39; # 进行歌ID筛选的正则表达式
hot_song_name = re.compile(pat2).findall(result) # 获取所有热门歌曲名称
hot_song_id = re.compile(pat3).findall(result) # 获取所有热门歌曲对应的Id
# print(hot_song_name)
# print(hot_song_id)
return hot_song_name, hot_song_id
# 抓取某一首歌的前page页评论
def get_all_comments(hot_song_id, page, hot_song_name, hot_song_order): # hot_song_order为了给文件命名添加一个编号
all_comments_list = [] # 存放所有评论
url = &#39;http://music.163.com/weapi/v1/resource/comments/R_SO_4_&#39; + hot_song_id + &#39;?csrf_token=&#39; # 歌评url
params =get_params(page)
encSecKey = get_encSecKey()
#data = {&#39;params&#39;: params, &#39;encSecKey&#39;: encSecKey}
html = get_json(url, params, encSecKey)
ht = json.loads(html)
# 评论总数
total = ht[&#39;total&#39;]
# 总页数
pages = int(math.ceil(total / 20))
print(&#39;第%d首歌曲: &#39; % (num+1)+ &#34;歌名:&#34;+ hot_song_name + &#34; 评论总数:&#34;+ str(total) + &#34; 评论页数:&#34;+ str(pages))
if __name__ == &#39;__main__&#39;:
start_time = time.time() # 开始时间
hot_song_name, hot_song_id = get_all_hotSong()
num = 0
while num < len(hot_song_name): # 保存所有热歌榜中的热评
#print(&#39;第%d首歌曲:&#39; % (num+1))
# 热门歌曲评论很多,每首爬取最新的70页评论
get_all_comments(hot_song_id[num], 70 , hot_song_name[num], num+1)
#print(&#39;第%d首歌曲热评抓取成功*********************** \n&#39; % (num+1))
num += 1
end_time = time.time() # 结束时间
print(&#39;程序耗时%f秒.&#39; % (end_time - start_time))运行结果如图:

很绝望,不管试了多少方法,都只能得到前10首歌曲的列表!最后还是通过文章开头介绍的方法得到了完整的了歌单列表,算是勉强满足了我此次的需求! |
|



 发表于 2022-12-1 18:13:54
发表于 2022-12-1 18:13:54